
Usefulness is not modality coordination #
This is how I have come to think about many multimodal large language models (MLLMs). The museum is the visual world, rich and structured and far larger than the set of questions we usually ask about it. The visitor requests are the language instructions used during training. The tour guide is the multimodal system: the visual encoder, the projector, and the language model trained to return the right answer when prompted. The professional test is our benchmark culture.
That multimodal models stumble on complex visual cases is widely documented; what I want to argue is more structural. Next-token prediction confines a model to a query-dependent "covered subspace", and it leaves the rest of the visual world under-determined no matter how far we scale. Not the encoder, not the data. The questions we train on.
The guide's success is real, and so is the success of current MLLMs. They are useful, impressive, often commercially valuable, and I understand why industry is excited, because a system that answers questions about images and follows visual instructions is already a powerful tool. But as researchers we are obliged to ask a sharper question, one that keeps apart two things the benchmark numbers quietly fuse together:
Does the model merely learn useful routes through the museum, or does it learn the map? Does it only retrieve answer-relevant visual information when queried, or does it acquire a representation in which vision and language are genuinely coordinated?
The distinction matters because question-answering usefulness is not the same as modality coordination. Strong performance shows that a model can route visual information into language generation when prompted; it does not, by itself, show that the model has learned a shared representational structure between the visual and linguistic worlds. The first is a conditional, query-indexed ability, the model asking given this question, which visual features should I surface? The second is what I will mean by coordination throughout: a structural property of the representation itself, independent of any particular query, in which visual and linguistic structure stand in a correspondence rich enough that interaction generalizes, so that new questions, new compositions, and counterfactual variations cross the interface smoothly, without a separately learned route waiting for each. In the parable, routing is the guide's repertoire; coordination is the map.
One clarification, because the words "gap" and "alignment" are both overloaded. There is a well-documented geometric modality gap, in which image and text embeddings in contrastive models like CLIP sit in separate cones at arm's length, an artifact traceable to initialization and the contrastive objective rather than to any failure of understanding.1, 2 In that literature, "alignment" often means no more than shrinking this distance, a property of point clouds in an embedding space. That is not the sense at stake here, and geometric proximity is neither necessary nor sufficient for coordination: a model can have a small geometric gap and still hold no map; conversely, it can have a large one and still answer well. So when I speak of the illusion of modality alignment, I do not mean a distance between two point clouds. I mean the inferential leap from retrieval works to the collection is organized, the habit of crediting a model with alignment, in the strong sense of coordination, on the evidence of fluent visual question answering. In both the museum and the model, that inference is tempting, and in both it may be wrong.
What visual instruction tuning actually rewards #

The issue is not that current MLLMs are built from a visual encoder, a projector, and a language model. The deeper issue, I believe, is the form of supervision---the instruction-response driven next-token prediction (NTP). Visual instruction tuning does not ask the model to reconstruct the visual world, to organize it, or even to coordinate it with language. It asks the model to produce the right answer tokens given an image and an instruction, and nothing more.3 Swapping the token-level likelihood for a preference reward changes none of this: the signal is still a score on answers drawn from a query distribution, so everything that follows applies to RLHF-style tuning unchanged (the support may move, the lock's logic does not).
Tellingly, the projector is often treated as little more than a shape adapter for dimensional compatibility. Even when we take its design seriously and build heavy abstract mappers, or structures that preserve local spatial features, the underlying problem remains.4 The projector is still trained entirely through the final instruction signal, so the bridge is shaped only by what is allowed to cross it.
This creates a supervision bottleneck. The image may carry rich visual structure, but the training signal reaches the model through a narrow channel: a question and an answer (or a caption as response during projector pretraining). Anything in the image that does not change the answer is invisible to the loss. It may sit in the pixels and even in the visual encoder, but if it never affects the answer tokens, the objective has no reason to expose it faithfully, let alone coordinate it with language. Under a finite capacity and compute budget, the path of least resistance is a shortcut, and the model learns whatever correlates with the right answer on the training queries while ignoring the rest. That is the regime in which out-of-distribution generalization degrades, counterfactual reasoning grows brittle, and hallucinations appear.
The symptoms are well-documented. The MMVP benchmark builds pairs of images that are visually distinct yet encoded almost identically by CLIP, and it shows that state-of-the-art MLLMs, GPT-4V among them, fail on strikingly simple questions about those pairs, often scoring below chance while confidently hallucinating explanations.5 The failures are systematic: the same visual patterns trip up many different models, which points to a shared cause rather than noise.
But is the information absent from the encoder, so that the book was never in the museum, or present yet unreachable, on a shelf with no route to it? This is the more diagnostic question. Recent work pulls the two apart by training probes directly on features from the visual encoder, from the intermediate projection, and from the language-model output, then comparing what each can recover. The finding is sobering: information a probe can read off the visual features can still fail to surface in the model's response. 6 The bottleneck, in other words, is often not perception but readout. The book is on a findable shelf, yet a route the training rewarded sends the guide back with the wrong one, the parable's wrong-cover book, a conflation that is learned rather than perceptual.
This dissociation is what the covered-subspace picture predicts. The deployed pipeline carries two covered subspaces, not one: the encoder's, shaped by the caption distribution of contrastive pretraining, and the readout's, shaped by the instruction distribution of tuning. A probe reads the first; the model's answer exposes only the second; and a direction has to fall inside both to make it from pixels to words. Information recoverable by probes yet missing from responses is just what a caption-covered, instruction-uncovered direction should look like. Read this way, the two benchmarks are not the same symptom at all: CLIP-blind pairs are failures of the first coverage, probe-readable but unsaid information of the second. This also answers a fair objection, that the encoder is not NTP-trained at all. True, and its coverage is caption-shaped rather than query-shaped; but the lock governs what the language model can be brought to say, and the argument needs only the readout half to bind.
This is why I do not think strong visual question-answering performance is sufficient evidence of modality coordination. The model may have learned the conditional structure needed for answering, routing specific features given a specific question, and that is a powerful ability. But it is strictly weaker than coordination, the learning of a shared representational structure between vision and language.
What language supervision can and cannot pin down #
A natural objection is that this is merely a data-scaling problem, and that the NTP paradigm itself is not to blame. It is a fair objection, and it is the field's default route: the assumption that with more diverse data and broader query coverage we can push the edge outward. Many results do show that scale improves performance, but it does so passively, as a by-product, rather than as something the objective is steering toward. To see why the edge never disappears, it helps to read language supervision through the lens of nonlinear independent component analysis (ICA).
Suppose the visual world is generated by nonlinearly mixing a set of latent factors of variation: objects, relations, events, and the causal structure among them. An intelligent agent's goal is to recover those factors, so that it can reason over the recovered states rather than over raw pixels. Here there is a foundational obstacle. Under the common assumption that the mixing is highly nonlinear, the latent factors are not identifiable without auxiliary structure: an infinity of equally valid solutions exists, and no amount of unsupervised data singles out the true one.7
Now the good news. Language is an abstract, disciplined auxiliary signal, and modern identifiability results are precisely about auxiliary variables. If an additional observed variable induces enough variation in the latent distribution, the true factors become recoverable up to simple, benign transformations. 8, 9 By forcing learning to follow language instructions, we push visual representations toward the way we describe and use the visual world. It is tempting to conclude that if we gather enough images and ask enough descriptive questions with human-preferred answers, we will recover more and more of the visual latents, eventually arriving at human-aligned visual understanding.
The identifiability theorems this leans on are proved for a particular object: a latent-variable model with a factorized prior conditioned on the auxiliary, fit by maximum likelihood. A next-token-trained vision-language model is not quite that object; it is a discriminative map from an image and a query to answer tokens. So I am using these results as a lens rather than a theorem, a way of seeing what language supervision can and cannot pin down. Whether the autoregressive objective inherits the same coverage-indexed identifiability is, to my knowledge, open. Taken as a lens, though, it has a sharp consequence, and that consequence turns on one condition.
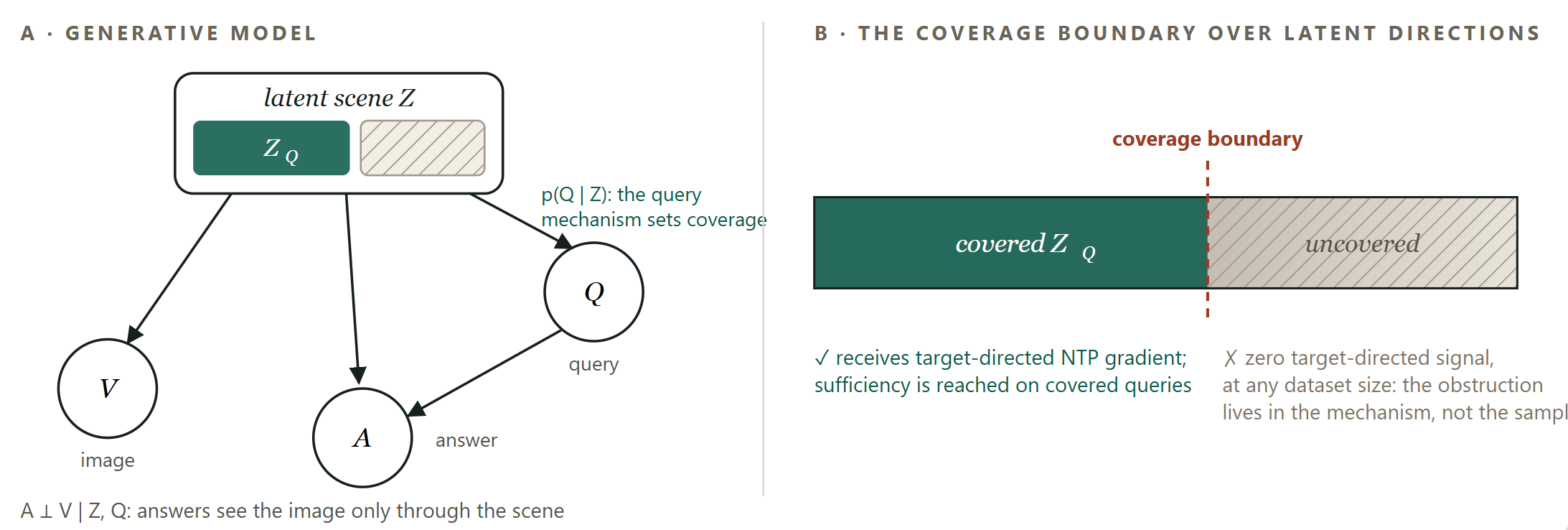
The condition is structural rather than incidental. The identifiability guarantee holds only under what is called a variability condition: the auxiliary signal must induce rich, independent variation across every latent direction it is meant to pin down. Language supervision satisfies that condition only over the subspace its queries actually exercise. Call this the covered subspace, the part of the museum the guide has been given routes to. Its shape is set by the distribution of training queries, not by the richness of the images, with the encoder held fixed.
The consequence is sharper than saying some things are missed. Even with infinite data and perfect optimization, the latents are identified only up to a coarsening; any two that produce the same answers on the supported queries stay indistinguishable. And this is where the optimism breaks: the directions outside the covered subspace are not left neutrally blank, waiting to be filled in later; they are under-determined. To see why, notice what the loss can actually feel. It scores the model only on the answer tokens assigned to a query, so it depends on a visual direction only insofar as that direction changes the answer distribution on the queries we ask. Take a direction that leaves every supported answer unchanged: moving along it moves no prediction, so the loss is not merely insensitive to it, it is flat along it. That flatness should be read in the right space. As a statement about the representation it is exact, since the objective supplies no goal-directed gradient along the direction, nothing to vanish and nothing for more data to sharpen. The parameters carrying the direction are another matter; shared weights, regularization, and finite-sample noise all move them. But they move under everything except the task, which is the sense in which the direction is under-determined rather than blank: its fate is decided by forces the queries never see. Scaling steepens a slope where a slope already exists; it cannot manufacture one where the loss is constant by construction.
The single exception is the hinge of the whole argument. If such a direction happens to correlate with something the queries reward, the loss is no longer flat, but the slope it acquires points toward using the direction as a cheap proxy rather than recovering it faithfully, and that slope vanishes on the counterfactuals where the correlation breaks. This compounds with the simplicity bias of neural networks: among predictive features the network commits to the simplest sufficient one and leaves the rest under-learned, 10 and once the cheap feature suffices, the gradient for the alternatives is starved.11 The correlated residual is not pruned as irrelevant; it is retained as a distribution-specific shadow. An uncorrelated residual has nothing to proxy for, so it stays arbitrary and a competent readout learns to ignore it, though not quite for free, since at finite width unconstrained directions still interfere with constrained ones. But that is a capacity tax, not a learned mistake. The harm is specific: it lives on the directions that coverage leaves under-determined and that the training distribution happens to make correlated.
None of this competes with simplicity bias; it sits one level upstream, and the same placement claim is owed to two larger neighbors. Shortcut learning names the phenomenon at the broadest grain: networks settle on decision rules that succeed on the training distribution and fail under shifts the intended solution would survive.12 Underspecification names the indeterminacy beneath it: many solutions fit the training signal equally well, and which one a pipeline returns is settled by arbitrary choices the objective never registers.13 Coverage says where, for multimodal NTP, both effects live and what selects them. Simplicity bias takes a correlated feature as given and predicts that the network will prefer it. Coverage decides which directions are left unconstrained and correlated for that preference to act on. The defining lever is the query distribution, not the images. Where the spurious-correlation literature locates the culprit in the visual data, the coverage reading lets you hold the images and the encoder fixed, vary only the questions asked, and watch a direction shift from an identified signal into an exploitable shadow. That a direction's fate hinges on the queries alone is what makes coverage a structural cause rather than a co-traveler of these better-known symptoms.
Take a world with two latent factors, shape and color, correlated in training: round things are red, square things are blue. Now ask only about shape. A model can drive its loss to zero by reading shape, or equally by reading color, which predicts shape perfectly here. Nothing decouples the two, so nothing in the objective prefers the honest solution; color is simply the cheaper route. The tangle surfaces only off-distribution: show a blue round object, ask its shape, and a model that latched onto color answers "square". Color was not pruned as irrelevant; it was retained as a spurious proxy, and it misleads the moment the correlation breaks, a learned mistake waiting for a distribution shift rather than a blank to be filled in later.

The coverage lock: relocated, never removed #
A direction can be harmless and still be uncovered. The damage, we saw, lives on the correlated residuals; an uncovered direction that correlates with nothing produces no wrong answers today. But coverage was never a claim about today's accuracy. It is a claim about reach: which directions the queries pin down at all, and what shape the covered subspace takes. An unexercised salience gap is a real loss of coverage even on a day it produces no error, because the question is what the model could be brought to represent, not what it happens to get wrong.
So why can scaling not close this? It can move the boundary, but it cannot remove it. Two forces hold the boundary in place, and both are problems of coverage, where the auxiliary signal is too sparse or too biased, and so both are in principle movable by better data:
- (M1) Salience bias of human annotation. There is a measurable latent subspace that human annotators do not find salient and therefore silently ignore. The signal is missing not because it is unimportant, but because no one thought to annotate it.
- (M2) Counterfactual scarcity. There is little what-if annotation in natural corpora. The data documents the world as it is, rarely as it could have been, yet counterfactual structure is what distinguishes a causal factor from a mere correlate.
The field has, to its credit, noticed some of this. M1 invites ever more careful data curation, cleaning, and annotation. M2 invites synthetic data and augmentation tools that turn observed scenes into new what-if variants, though one might ask whether genuinely intrinsic counterfactuals can be manufactured this way at all.
Notice what the two forces have in common: both are, in principle, movable by better data, and yet the lock holds anyway. This is what I mean by the coverage lock. Two claims meet here, and they live in different likelihoods. The load-bearing one is about the model's own objective: next-token prediction, the conditional likelihood of answer tokens given an image and a query, supplies no goal-directed gradient along answer-irrelevant directions, and that silence is what leaves the residual directions under-determined. The lens adds the second: read through nonlinear ICA, those directions are non-identified latent factors, pinned down only up to a coarsening at fixed query coverage. The harm and the prescription rest on the first; the lens only supplies the name, and whether the autoregressive objective formally inherits its identifiability is, as flagged above, open. So the burden on anyone who wants out of the lock holds whether or not the lens transfers. At fixed query support the objective is silent along the residual directions, and data spoken in that objective's language helps only by changing the support, by writing queries that exercise a direction nothing previously asked about. That route is open, and M1 and M2 say precisely that it is. But it is a treadmill, and a blind one: by M1 you would already need the map to know which queries are missing, so every expressible gap must be closed by hand, one annotation campaign at a time, with no signal from the objective about where the next gap lies. The lock is not that data cannot move the boundary. It is that the objective cannot tell you where the boundary is, and will not pay you to move it. Change the objective, not just the data.
From the map to the territory: open questions #
If usefulness is not faithful modality coordination, then the constructive task is to stop reading retrieval as organization, and to start measuring, and eventually building, the map itself. I do not have these answers, but I think they are among the more tractable problems hiding inside the philosophy above. Here is where I would ask.
- Q1. How do we read the geometry inside the LLM? The thesis of this post is geometric in spirit, framing a covered subspace and an under-determined residue, but I have stated it abstractly. There is now a concrete vocabulary for the internal geometry of language models: under the linear representation hypothesis, concepts appear as linear directions, categorical concepts as simplices and polytopes, and hierarchical relations as orthogonality between directions.14 The open question is whether the covered subspace is visible as a geometric object in this internal space, and whether the coverage boundary has a signature, for instance as directions along which no consistent linear readout exists. If modality coordination has a geometry, we should be able to point to it. It would live here, in the model's internal concept space, a different object entirely from the inter-modal distance set aside earlier.
- Q2. Can we measure coverage directly? The idea of a supervised coverage gap should not stay a metaphor. For a given query distribution, can we estimate which visual latent directions are exercised and which are left under-determined? This would turn coverage into a quantity we can compute, compare across datasets, and use to predict where a model will fail before it does. It would also discharge the argument's main empirical debt. The flatness argument above is true largely by construction; the claim that does the real work, and the one I have not shown, is that the residual subspace is non-trivial, high-dimensional enough to matter. That is the assumption everything else leans on, and the measurement proposed here is exactly its test.
- Q3. Can we catch spurious retention in the act? Correlated residuals are directions outside coverage that the training distribution nonetheless ties to covered ones. If these are retained as distribution-specific shadows, they should betray themselves under intervention. Concretely, take counterfactual image-text pairs that differ only along one such direction and check whether the model's answer changes when it should not, or fails to change when it should. That non-invariance is the fingerprint of a retained shadow. This is a diagnostic rather than a training regime, which sidesteps the (M2) worry above: even synthetic edits that are not genuinely intrinsic counterfactuals are enough to expose non-invariance, and gathering data at diagnostic scale costs a fraction of what training-scale coverage would. 15 A positive result would convert a theoretical mechanism into a clean, efficient probe without paying the data-scaling bill.
- Q4. What lies beyond likelihood? If NTP supplies no pressure along residual directions, the question is which auxiliary objectives would, in a principled rather than ad hoc way. Candidates include genuinely interventional what-if data, reconstruction objectives that reward exposing answer-irrelevant structure, and multi-view or contrastive signals that constrain the representation from a second angle. The goal is to expand the covered subspace by design, not just by accumulating more annotation. One honesty requirement for this program: none of the candidates is coverage-free. Reconstruction is silent about whatever the decoder need not render to score well; multi-view signals constrain only the directions the views actually vary; contrastive pairing inherits the coverage, and the selection biases 16, of however the pairs were gathered. Coverage is a property of any objective-and-data pair, so the claim here is comparative rather than absolute: NTP's covered subspace is uniquely query-shaped and blind to its own boundary, not that some rival sees everything. The realistic engineering question is composition, which objectives have complementary covered subspaces, so that the union grows exactly where each alone is silent.
- Q5. Where is the expressibility frontier, and does it matter? This is the honest open problem, and it needs stating carefully now that harm has been localized. An inexpressible distinction that still correlates with some expressible query is just the simplicity-bias hazard above in new dress; one that correlates with nothing is the harmless, arbitrary case. The genuine frontier is the narrower residue that is both unsayable and uncorrelated with anything sayable, and whether that residue is even non-empty is the controversial part. It shades into a philosophical question: if some information is inexpressible in natural language, is it even useful to a human, or to a human-aligned agent? I lean toward yes. If our ambition is real visual understanding and not merely a strong tool, then the inexpressible residue is where the most interesting structure may hide, which is also why I do not think the question is rhetorical.
The tour guide can be excellent for a lifetime and still never hold a map. A strong MLLM can top every benchmark we have built and still leave vision and language merely routed rather than coordinated. Recognizing the difference is the first step. Measuring it, and then closing it on purpose rather than by accident, is the real work.
References #
- W. Liang, Y. Zhang, Y. Kwon, S. Yeung, and J. Zou. Mind the Gap: Understanding the Modality Gap in Multi-modal Contrastive Representation Learning. NeurIPS, 2022. arXiv:2203.02053
- Y. Cai, Z. Zhang, Y. Liu, and J. Q. Shi. The Geometric Mechanics of Contrastive Representation Learning: Alignment Potentials, Entropic Dispersion, and Cross-modal Divergence. ICML, 2026. arXiv:2601.19597
- H. Liu, C. Li, Q. Wu, and Y. J. Lee. Visual Instruction Tuning. NeurIPS, 2023. arXiv:2304.08485
- J. Cha, W. Kang, J. Mun, and B. Roh. Honeybee: Locality-enhanced Projector for Multimodal LLM. CVPR, 2024. arXiv:2312.06742
- S. Tong, Z. Liu, Y. Zhai, Y. Ma, Y. LeCun, and S. Xie. Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs. CVPR, 2024. arXiv:2401.06209
- S. Chandhok, W.-C. Fan, V. Shwartz, V. N. Balasubramanian, and L. Sigal. Response Wide Shut? Surprising Observations in Basic Vision Language Model Capabilities. ACL, 2025. arXiv:2507.10442
- A. Hyvärinen and P. Pajunen. Nonlinear independent component analysis: Existence and uniqueness results. Neural Networks, 12(3):429–439, 1999. doi:10.1016/S0893-6080(98)00140-3
- A. Hyvärinen, H. Sasaki, and R. E. Turner. Nonlinear ICA Using Auxiliary Variables and Generalized Contrastive Learning. AISTATS, 2019. arXiv:1805.08651
- I. Khemakhem, D. P. Kingma, R. P. Monti, and A. Hyvärinen. Variational Autoencoders and Nonlinear ICA: A Unifying Framework. AISTATS, 2020. arXiv:1907.04809
- H. Shah, K. Tamuly, A. Raghunathan, P. Jain, P. Netrapalli. The Pitfalls of Simplicity Bias in Neural Networks. NeurIPS, 2020. arXiv:2006.07710
- M. Pezeshki, S.-O. Kaba, Y. Bengio, A. Courville, D. Precup, and G. Lajoie. Gradient Starvation: A Learning Proclivity in Neural Networks. NeurIPS, 2021. arXiv:2011.09468
- R. Geirhos, J.-H. Jacobsen, C. Michaelis, R. Zemel, W. Brendel, M. Bethge, and F. A. Wichmann. Shortcut Learning in Deep Neural Networks. Nature Machine Intelligence, 2020. arXiv:2004.07780
- A. D'Amour, K. Heller, D. Moldovan, B. Adlam, B. Alipanahi, A. Beutel, C. Chen, J. Deaton, J. Eisenstein, M. D. Hoffman, F. Hormozdiari, N. Houlsby, S. Hou, G. Jerfel, A. Karthikesalingam, M. Lucic, Y. Ma, C. McLean, D. Mincu, A. Mitani, A. Montanari, Z. Nado, V. Natarajan, C. Nielson, T. F. Osborne, R. Raman, K. Ramasamy, R. Sayres, J. Schrouff, M. Seneviratne, S. Sequeira, H. Suresh, V. Veitch, M. Vladymyrov, X. Wang, K. Webster, S. Yadlowsky, T. Yun, X. Zhai, and D. Sculley. Underspecification Presents Challenges for Credibility in Modern Machine Learning. JMLR, 2022. arXiv:2011.03395
- K. Park, Y. J. Choe, Y. Jiang, and V. Veitch. The Geometry of Categorical and Hierarchical Concepts in Large Language Models. ICLR, 2025. arXiv:2406.01506
- T. Le, V. Lal, and P. Howard. COCO-Counterfactuals: Automatically Constructed Counterfactual Examples for Image-Text Pairs. NeurIPS, 2023. arXiv:2309.14356
- Y. Cai, Y. Liu, E. Gao, T. Jiang, Z. Zhang, A. van den Hengel, and J. Q. Shi. On the Value of Cross-Modal Misalignment in Multimodal Representation Learning. NeurIPS, 2025. arXiv:2504.10143