Yichao Cai
Understanding how learning objectives shapes the representations.

yichao.cai@adelaide.edu.au
I am a PhD student in Computer Science at the Australian Institute for Machine Learning (AIML), Adelaide University, advised by Prof. Javen Qinfeng Shi. I received my M.Sc. and B.Eng. degrees from Wuhan University of Technology and spent five months as a visiting student researcher at California PATH, UC Berkeley.
My research studies how modern learning objectives and supervision signals shape learned representations. I am particularly interested in when learning objectives identify causal and generalizable latent structure, and when they instead discard, conflate, or leave such structure underdetermined. Understanding these questions helps characterize the theoretical limits of foundation model objectives and distinguishes which capabilities emerge through scaling from those requiring new objectives, supervision forms, or data interventions.
Methodologically, I use tools from identifiability theory, latent-variable modeling, population-objective analysis, and representation geometry. My broader goal is to develop a theory of representation learning that explains the capabilities and structural limits of modern representation models.
News
| Jun 12, 2026 | New essay: The Coverage Lock—why scaling cannot teach a multimodal model what its training questions never ask about. |
|---|---|
| May 01, 2026 | We had 3 papers on representation learning (contrastive learning theory, AI4Science, and graphical modeling) accepted to ICML 2026. |
| Feb 10, 2026 | I attended MLSS Melbourne 2026 and enjoyed learning from world-class speakers and connecting with the community. |
| Jan 28, 2026 | Check out our new preprint: The Geometric Mechanics of Contrastive Representation Learning. |
| Oct 15, 2025 | I served as a guest lecturer in Statistical Machine Learning and presented recent advances in vision-language modeling. Slides. |
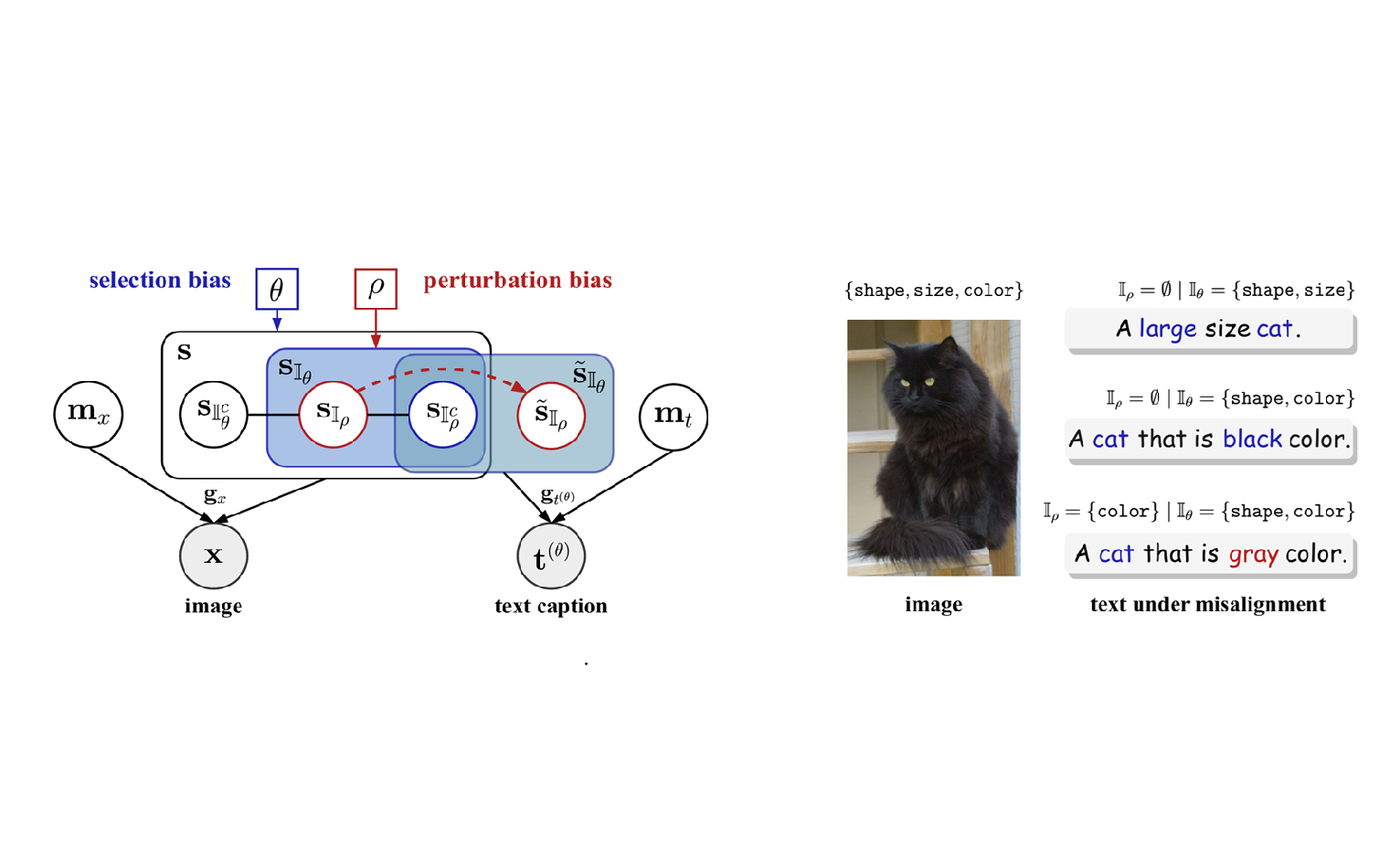
| Sep 19, 2025 | Our work On the Value of Cross-Modal Misalignment in Multimodal Representation Learning was selected as a Spotlight at NeurIPS 2025. |
| Apr 14, 2025 | We released the preprint On the Value of Cross-Modal Misalignment in Multimodal Representation Learning. |
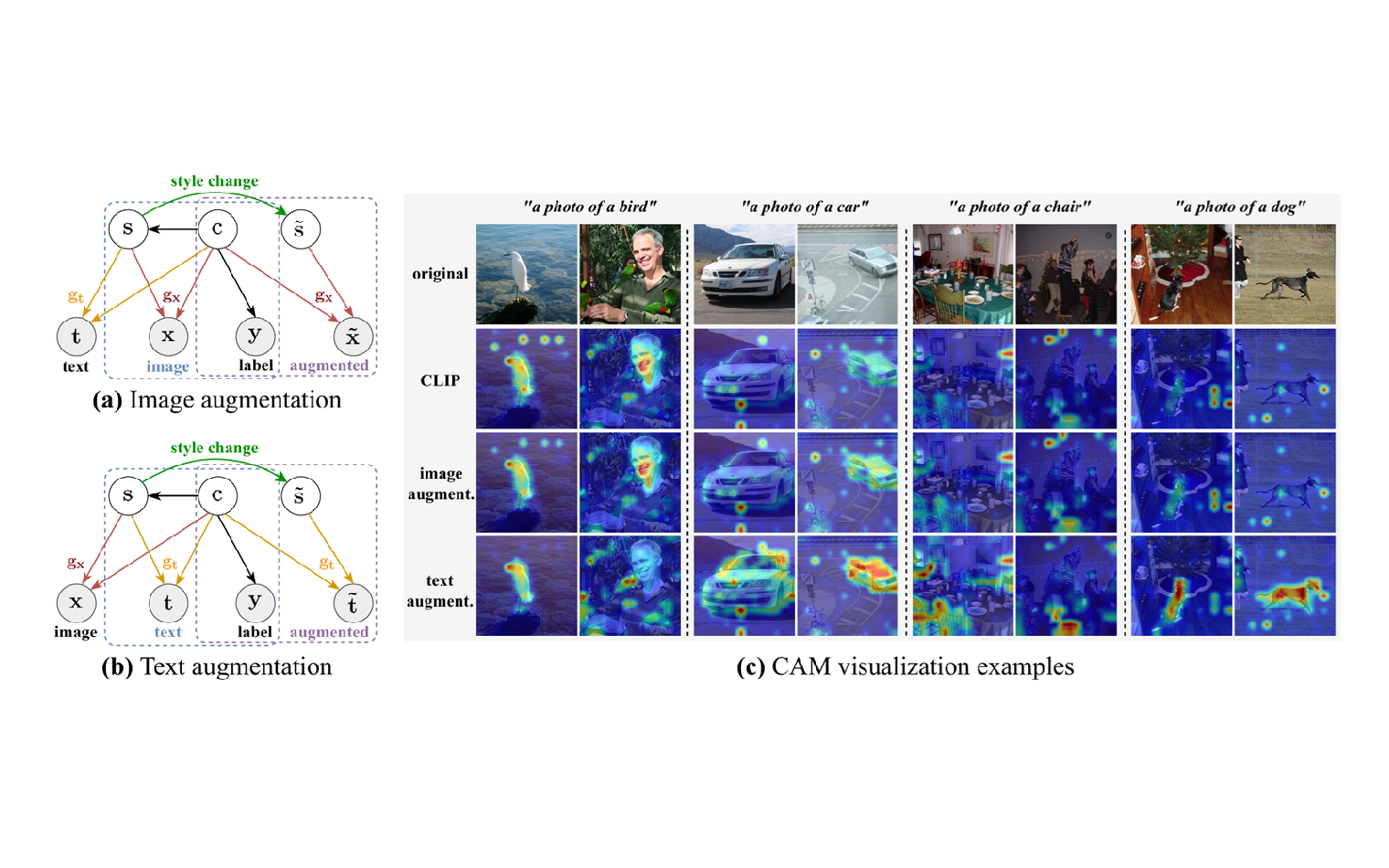
| Jul 02, 2024 | Our work CLAP: Isolating Content from Style through Contrastive Learning with Augmented Prompts was accepted at ECCV 2024. |
Research
Selected publications are highlighted.
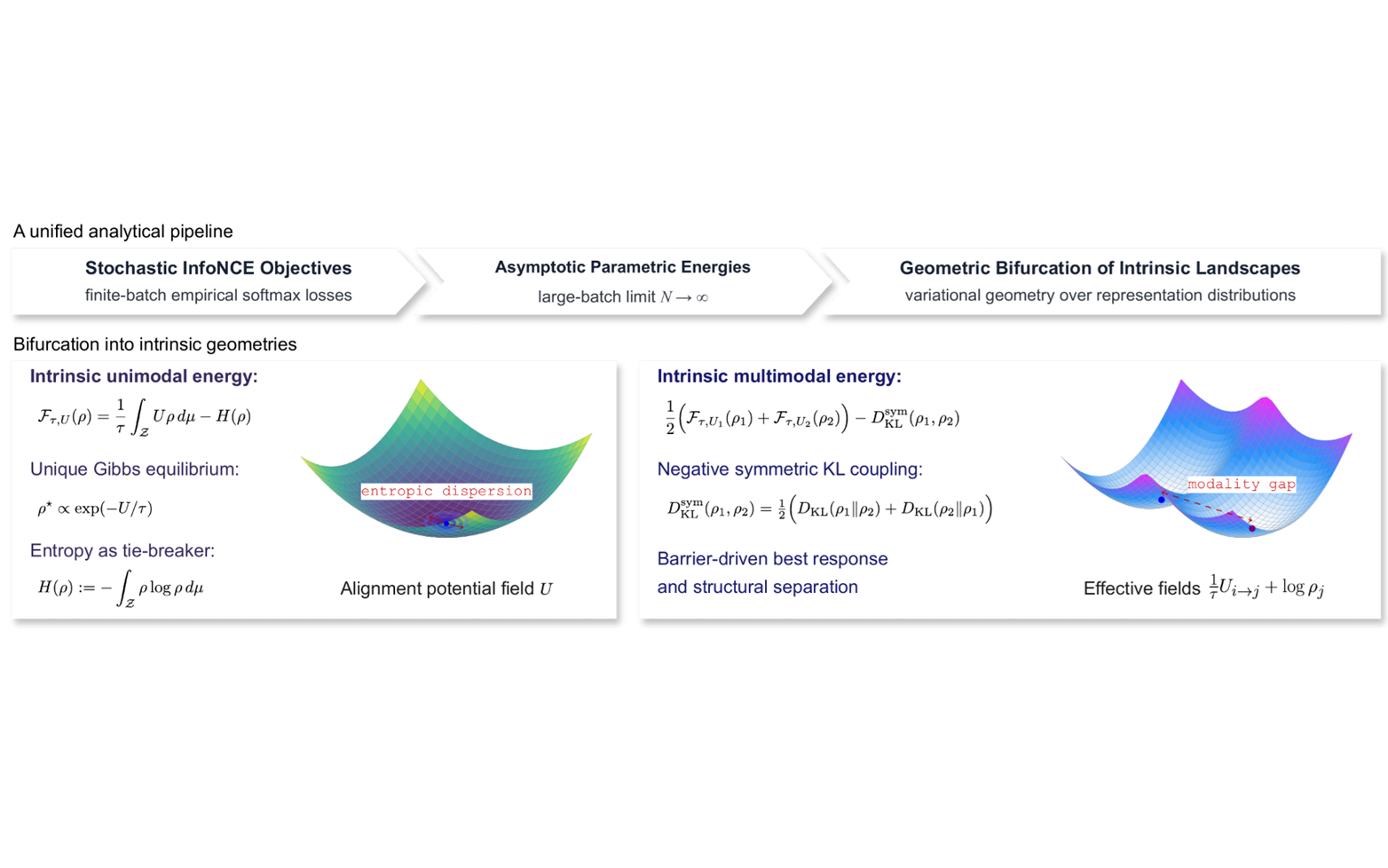
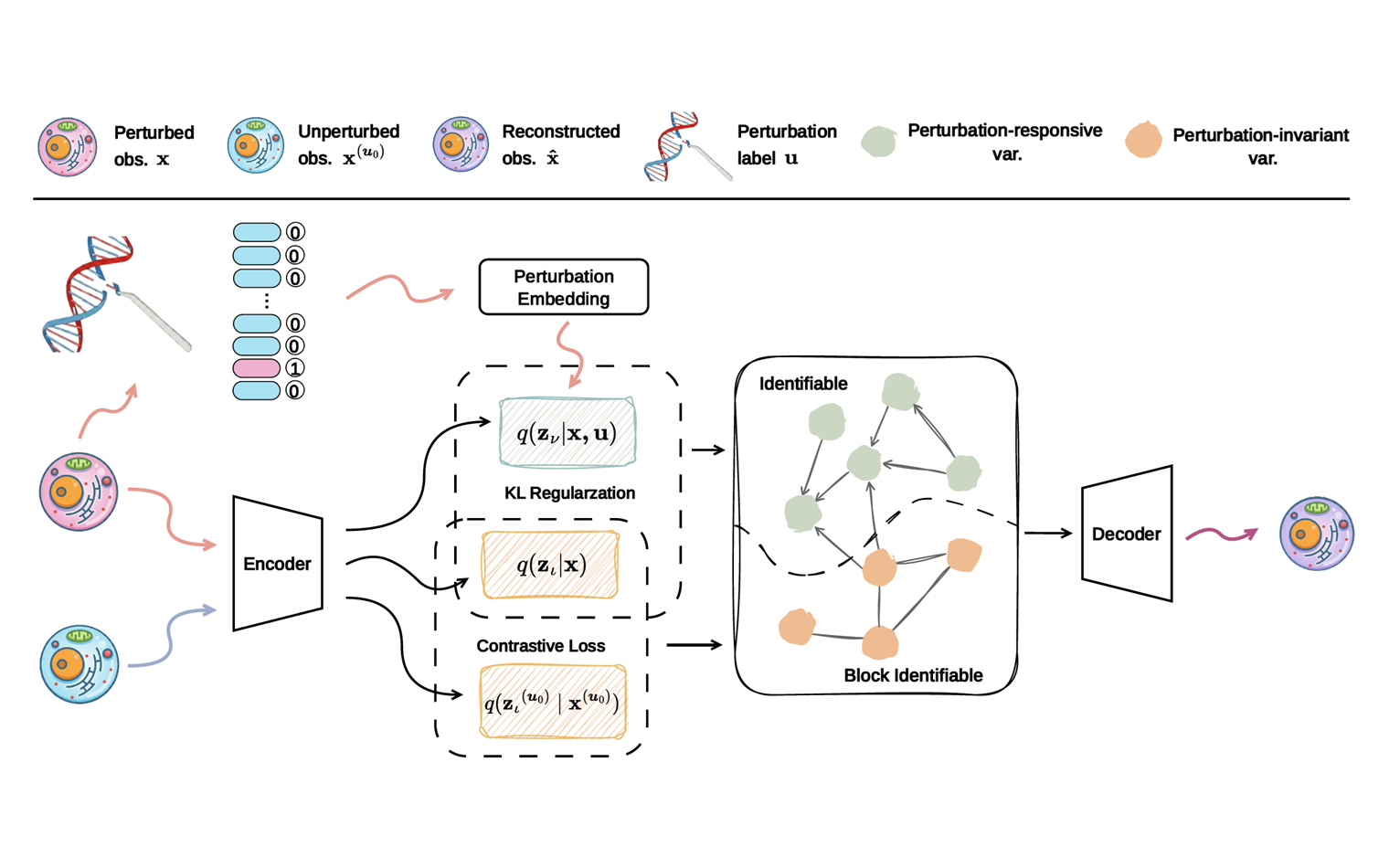
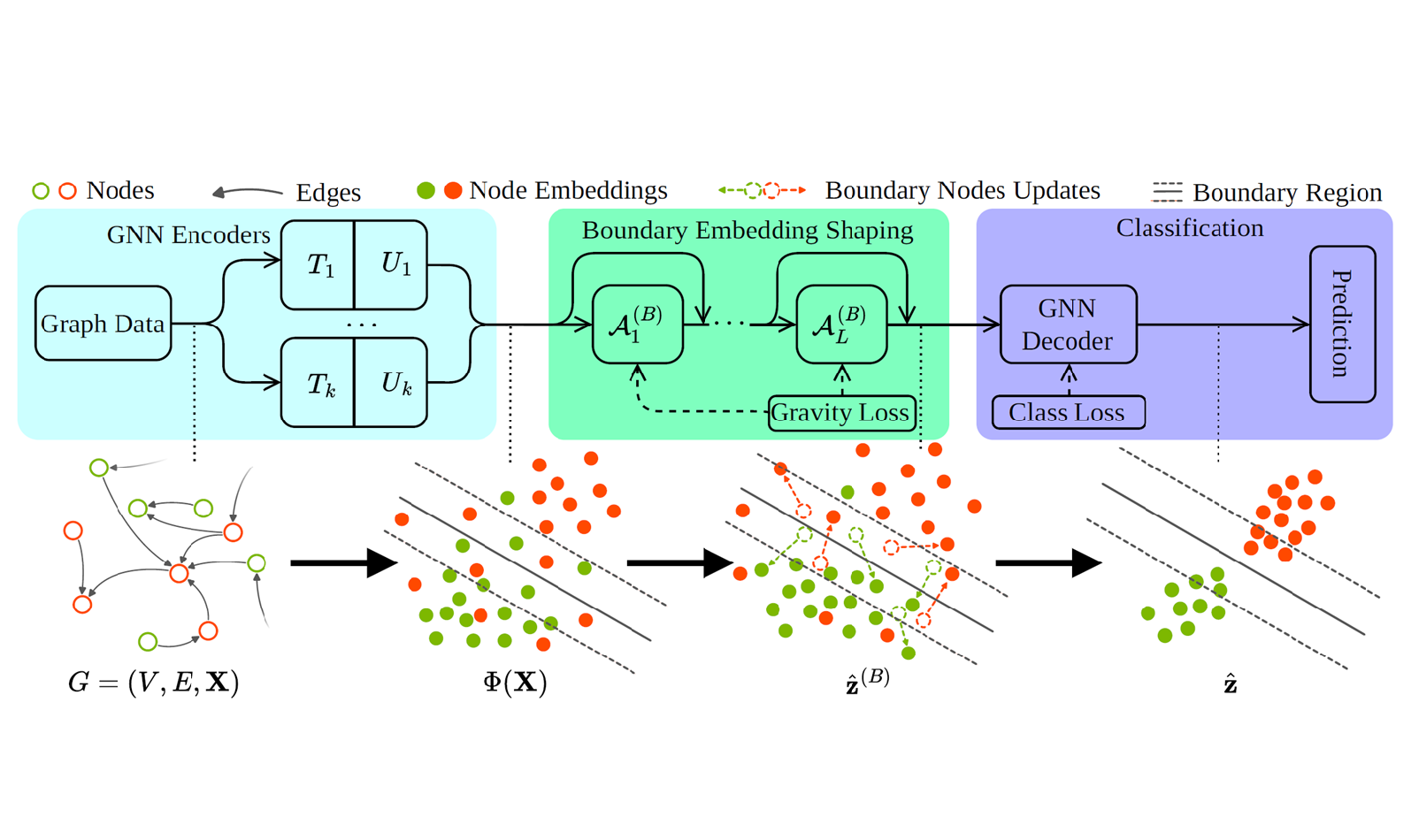
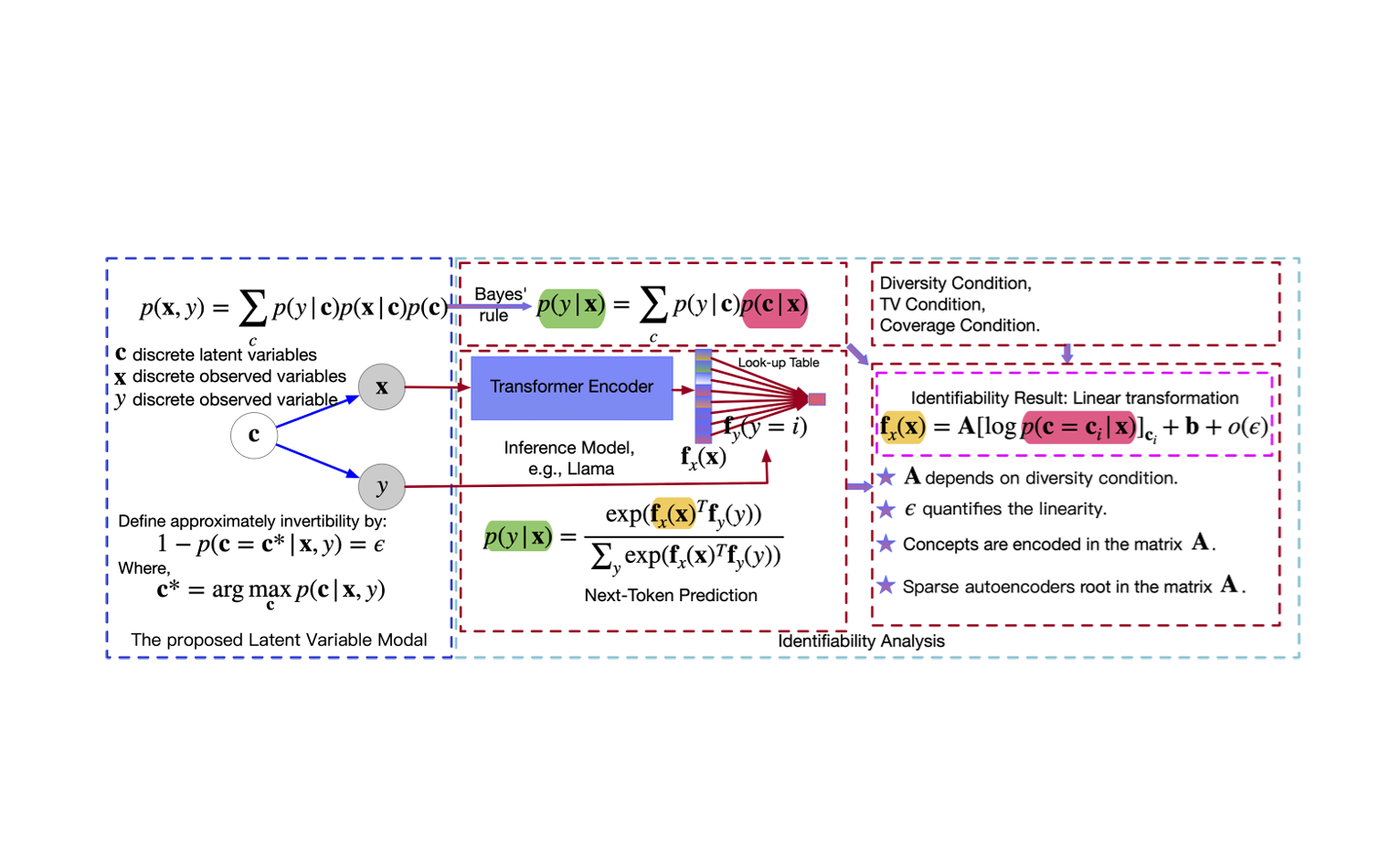
Teaching
At Adelaide University (formerly The University of Adelaide):
- Semester 1, 2026 Teaching Assistant, Neural Networks and Deep Learning (ARTI X300)
- Semester 2, 2025 Guest Lecturer & Head Tutor, Statistical Machine Learning (COMP SCI 3314).
- Trimester 2, 2025 Teaching Assistant, Using Machine Learning Tools (COMP SCI 7317)
- Semester 1, 2025 Teaching Assistant, Concepts in AI and ML (COMP SCI 7327)
Academic Service
Conference Reviewer:
- International Conference on Learning Representations (ICLR) 2026
- International Conference on Machine Learning (ICML) 2026, Silver Reviewer Award
- Conference on Neural Information Processing Systems (NeurIPS) 2026
Journal Reviewer:
- Transactions on Machine Learning Research (TMLR)