Representative papers are
highlighted.
2026

ICML 2026
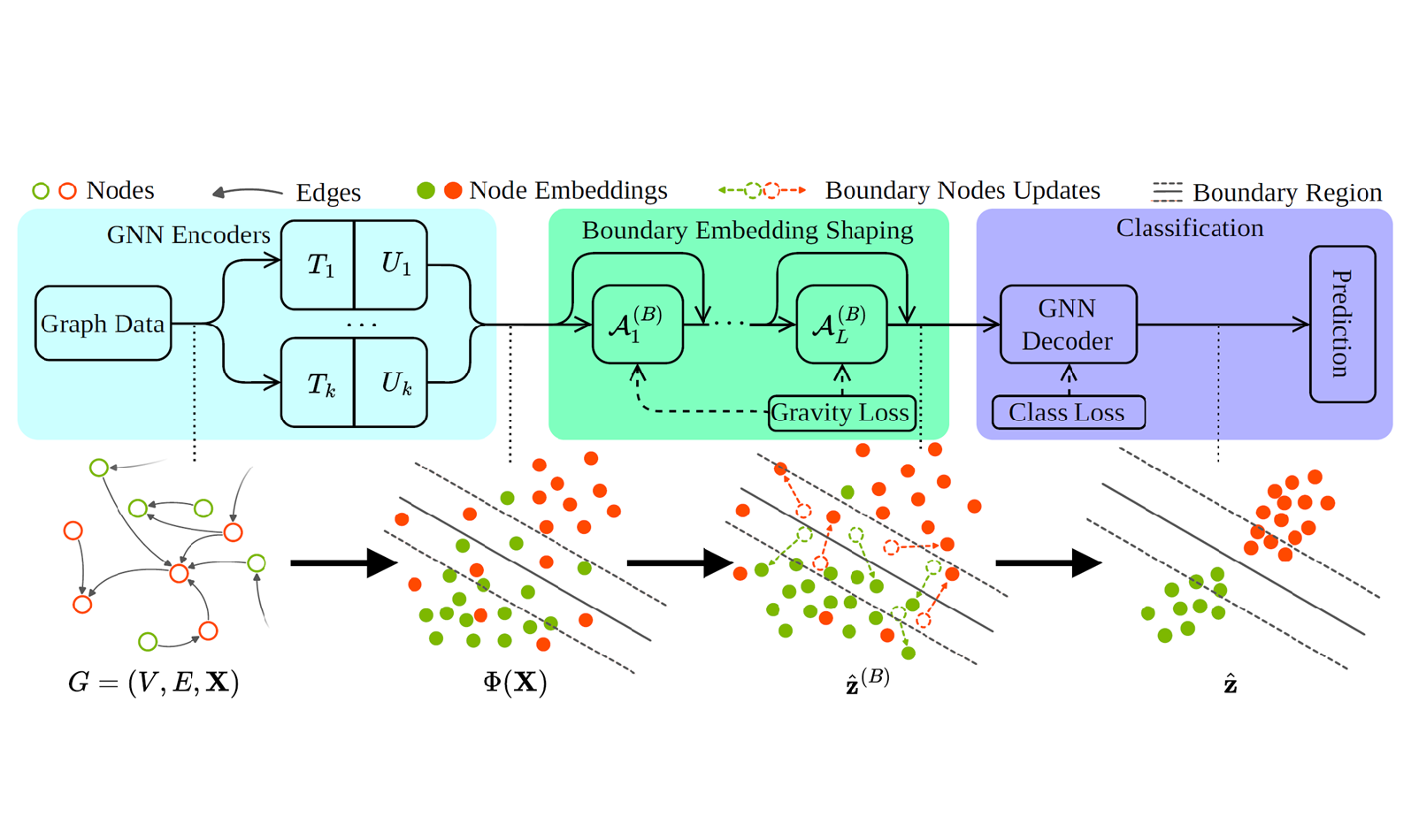
Boundary Embedding Shaping with Adaptive Contrastive Learning for Graph Structural Disentanglement
Boundary Embedding Shaping with Adaptive Contrastive Learning for Graph Structural Disentanglement
ICML 2026
ICML 2026
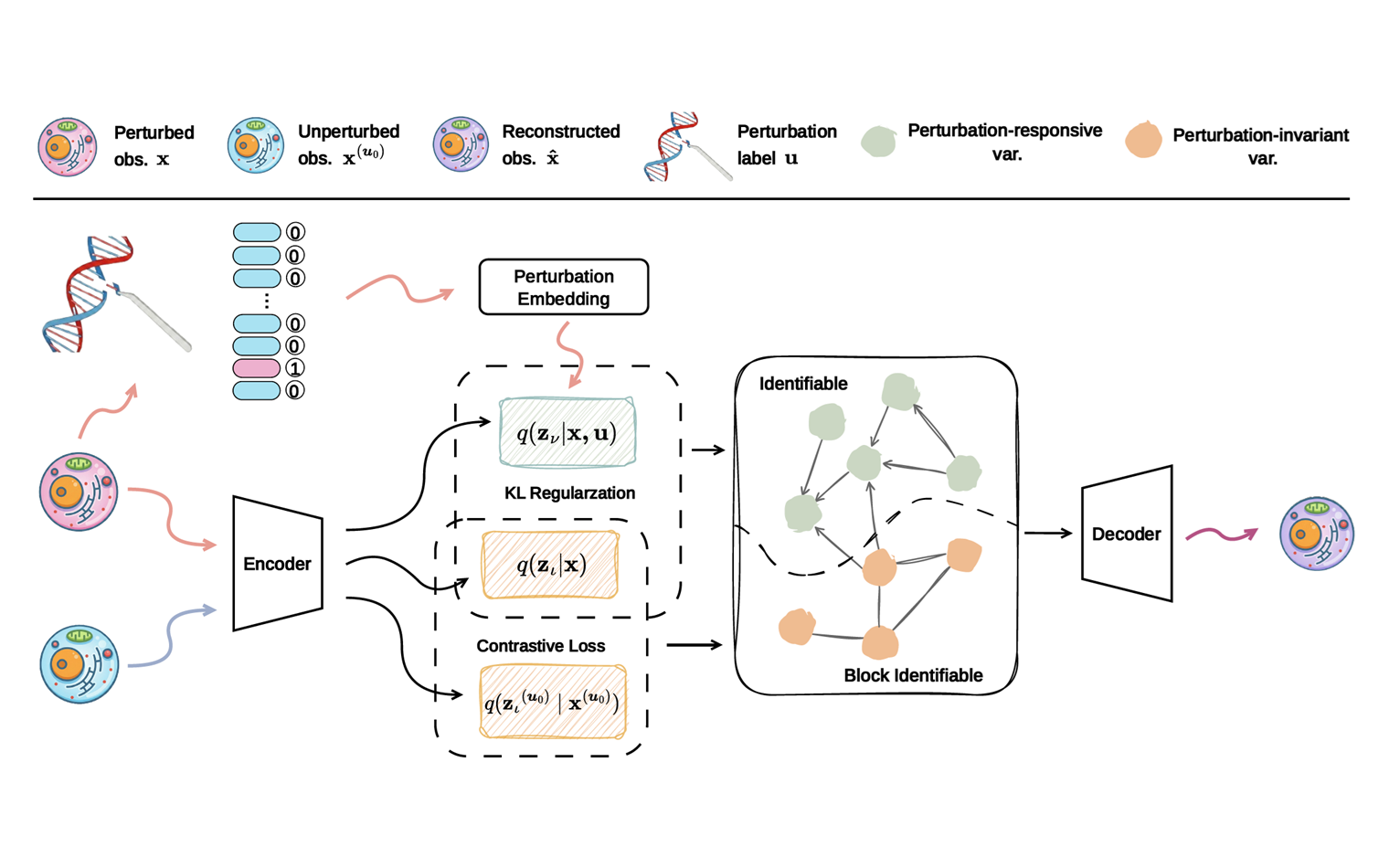
What Makes a Good Representation for Single-Cell Perturbation Prediction?
What Makes a Good Representation for Single-Cell Perturbation Prediction?
ICML 2026