publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
- A Preprint
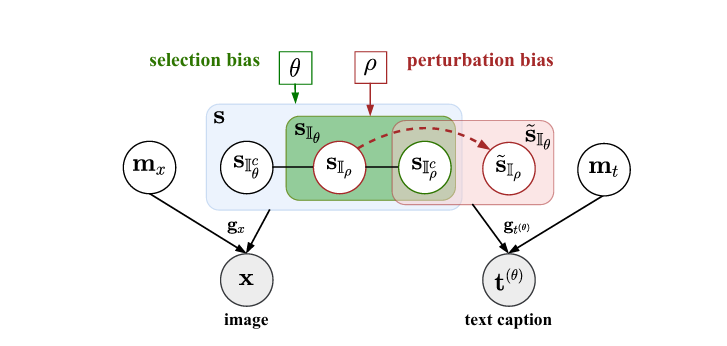 On the Value of Cross-Modal Misalignment in Multimodal Representation LearningYichao Cai, Yuhang Liu, Erdun Gao, Tianjiao Jiang, Zhen Zhang, Anton Hengel, and Javen Qinfeng Shi2025
On the Value of Cross-Modal Misalignment in Multimodal Representation LearningYichao Cai, Yuhang Liu, Erdun Gao, Tianjiao Jiang, Zhen Zhang, Anton Hengel, and Javen Qinfeng Shi2025Multimodal representation learning, exemplified by multimodal contrastive learning (MMCL) using image-text pairs, aims to learn powerful representations by aligning cues across modalities. This approach relies on the core assumption that the exemplar image-text pairs constitute two representations of an identical concept. However, recent research has revealed that real-world datasets often exhibit cross-modal misalignment. There are two distinct viewpoints on how to address this issue: one suggests mitigating the misalignment, and the other leveraging it. We seek here to reconcile these seemingly opposing perspectives, and to provide a practical guide for practitioners. Using latent variable models we thus formalize cross-modal misalignment by introducing two specific mechanisms: Selection bias, where some semantic variables are absent in the text, and perturbation bias, where semantic variables are altered – both leading to misalignment in data pairs. Our theoretical analysis demonstrates that, under mild assumptions, the representations learned by MMCL capture exactly the information related to the subset of the semantic variables invariant to selection and perturbation biases. This provides a unified perspective for understanding misalignment. Based on this, we further offer actionable insights into how misalignment should inform the design of real-world ML systems. We validate our theoretical findings via extensive empirical studies on both synthetic data and real image-text datasets, shedding light on the nuanced impact of cross-modal misalignment on multimodal representation learning.
- A Preprint
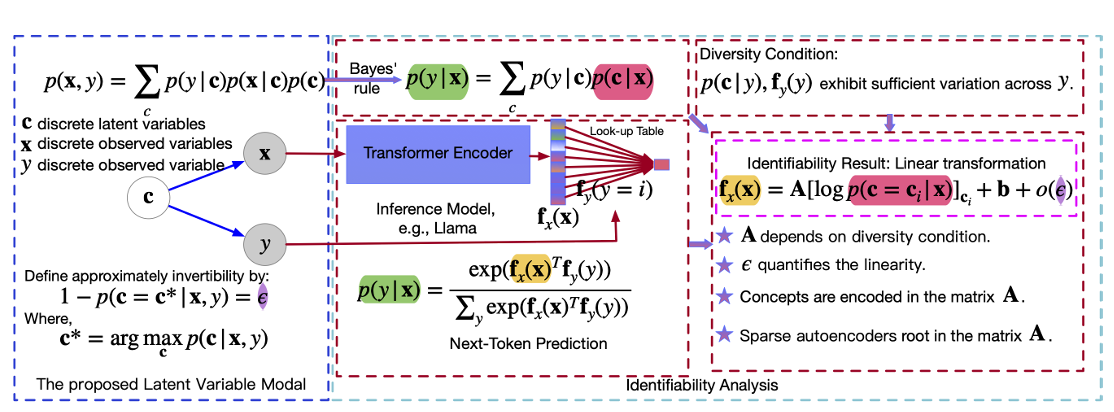 I Predict Therefore I Am: Is Next Token Prediction Enough to Learn Human-Interpretable Concepts from Data?Yuhang Liu, Dong Gong, Yichao Cai, Erdun Gao, Zhen Zhang, Biwei Huang, Mingming Gong, Anton Hengel, and Javen Qinfeng ShiarXiv e-prints, 2025
I Predict Therefore I Am: Is Next Token Prediction Enough to Learn Human-Interpretable Concepts from Data?Yuhang Liu, Dong Gong, Yichao Cai, Erdun Gao, Zhen Zhang, Biwei Huang, Mingming Gong, Anton Hengel, and Javen Qinfeng ShiarXiv e-prints, 2025The remarkable achievements of large language models (LLMs) have led many to conclude that they exhibit a form of intelligence. This is as opposed to explanations of their capabilities based on their ability to perform relatively simple manipulations of vast volumes of data. To illuminate the distinction between these explanations, we introduce a novel generative model that generates tokens on the basis of human-interpretable concepts represented as latent discrete variables. Under mild conditions, even when the mapping from the latent space to the observed space is non-invertible, we establish an identifiability result, i.e., the representations learned by LLMs through next-token prediction can be approximately modeled as the logarithm of the posterior probabilities of these latent discrete concepts given input context, up to an invertible linear transformation. This theoretical finding not only provides evidence that LLMs capture underlying generative factors, but also provide a unified prospective for understanding of the linear representation hypothesis. Taking this a step further, our finding motivates a reliable evaluation of sparse autoencoders by treating the performance of supervised concept extractors as an upper bound. Pushing this idea even further, it inspires a structural variant that enforces dependence among latent concepts in addition to promoting sparsity. Empirically, we validate our theoretical results through evaluations on both simulation data and the Pythia, Llama, and DeepSeek model families, and demonstrate the effectiveness of our structured sparse autoencoder.


2024
- ECCV 2024
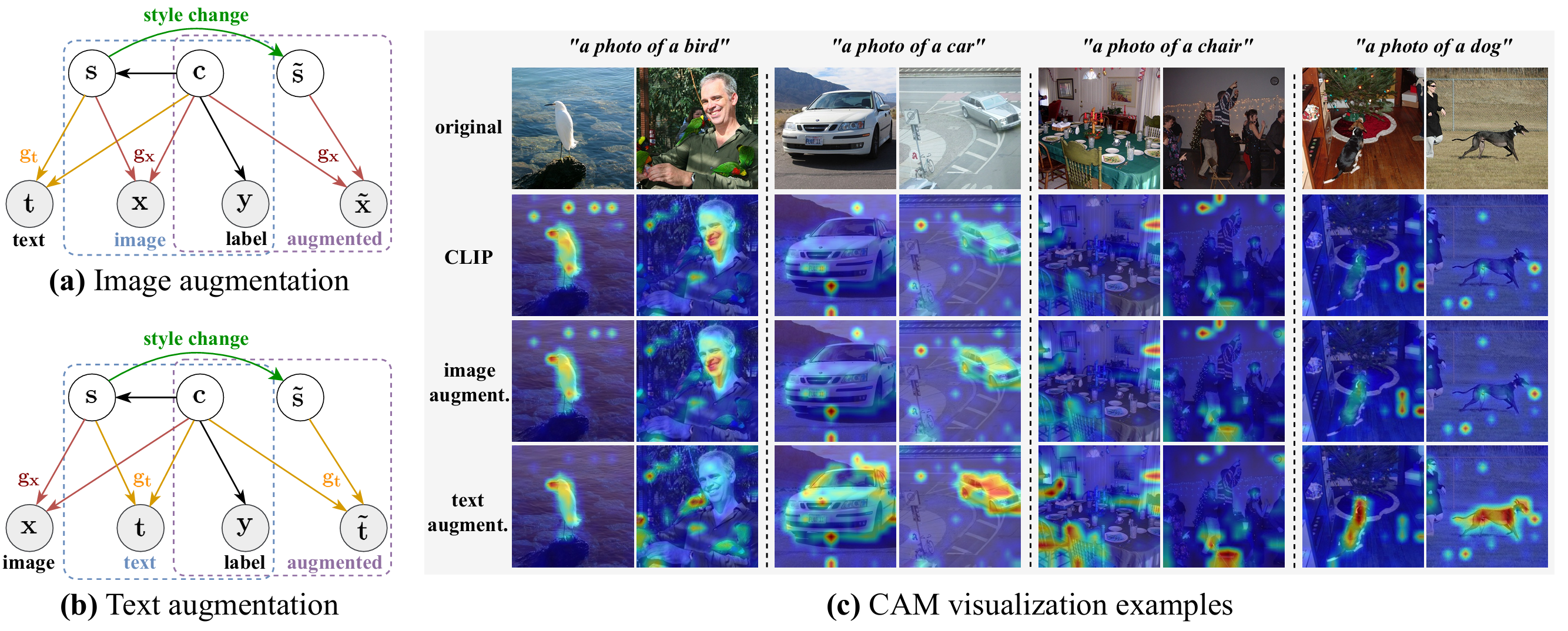 CLAP: Isolating Content from Style through Contrastive Learning with Augmented PromptsYichao Cai, Yuhang Liu, Zhen Zhang, and Javen Qinfeng ShiIn Computer Vision - ECCV 2024: 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XXI, Milan, Italy, 2024
CLAP: Isolating Content from Style through Contrastive Learning with Augmented PromptsYichao Cai, Yuhang Liu, Zhen Zhang, and Javen Qinfeng ShiIn Computer Vision - ECCV 2024: 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XXI, Milan, Italy, 2024Contrastive vision-language models, such as CLIP, have garnered considerable attention for various dowmsteam tasks, mainly due to the remarkable ability of the learned features for generalization. However, the features they learned often blend content and style information, which somewhat limits their generalization capabilities under distribution shifts. To address this limitation, we adopt a causal generative perspective for multimodal data and propose contrastive learning with data augmentation to disentangle content features from the original representations. To achieve this, we begin with exploring image augmentation techniques and develop a method to seamlessly integrate them into pre-trained CLIP-like models to extract pure content features. Taking a step further, recognizing the inherent semantic richness and logical structure of text data, we explore the use of text augmentation to isolate latent content from style features. This enables CLIP-like model’s encoders to concentrate on latent content information, refining the learned representations by pre-trained CLIP-like models. Our extensive experiments across diverse datasets demonstrate significant improvements in zero-shot and few-shot classification tasks, alongside enhanced robustness to various perturbations. These results underscore the effectiveness of our proposed methods in refining vision-language representations and advancing the state-of-the-art in multimodal learning.

2023
- ICUS 2023
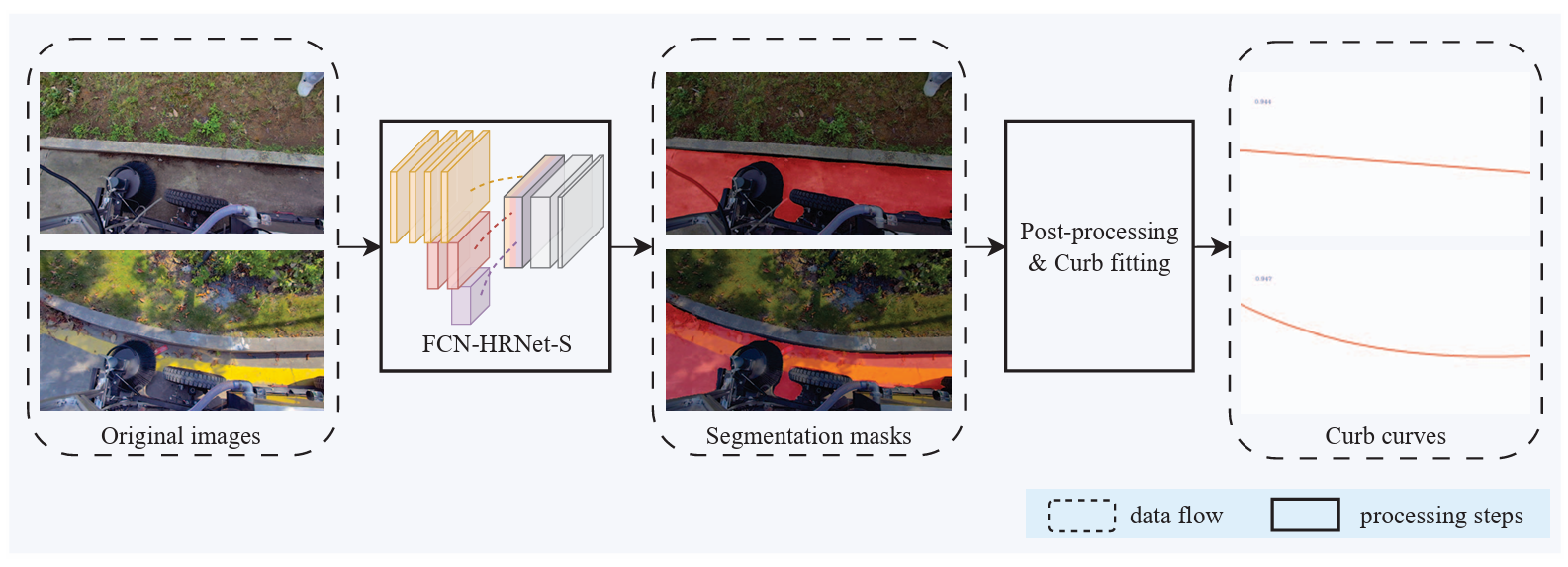 Robust Real-Time Curb Detection for Autonomous Sanitation VehiclesYichao Cai, Kejun Ou, Dachuan Li, Yuanfang Zhang, Xiao Zhou, and Xingang MouIn 2023 IEEE International Conference on Unmanned Systems (ICUS), 2023
Robust Real-Time Curb Detection for Autonomous Sanitation VehiclesYichao Cai, Kejun Ou, Dachuan Li, Yuanfang Zhang, Xiao Zhou, and Xingang MouIn 2023 IEEE International Conference on Unmanned Systems (ICUS), 2023Curb detection is a key enabling functionality for the precise curb-following sanitation control of autonomous sanitation vehicles. The robust and efficient curb detection in complex environments is still a challenging issue. In this paper, we propose a novel semantic segmentation-based framework for curb detection using monocular bird’s eye-view images. We employ a lightweight segmentation network based on HRNet to extract the drivable area. A zero-shot post-processing approach is proposed to extract a candidate point set from the segmented image for robust curve fitting. In addition, we propose a modified RANSAC fitting approach that accounts for outlier points to achieve dynamic order curve fitting and curb representation. Experimental results in complex sanitation scenarios demonstrate the efficiency, accuracy, and robustness of the proposed approach.

2018
- Sensors
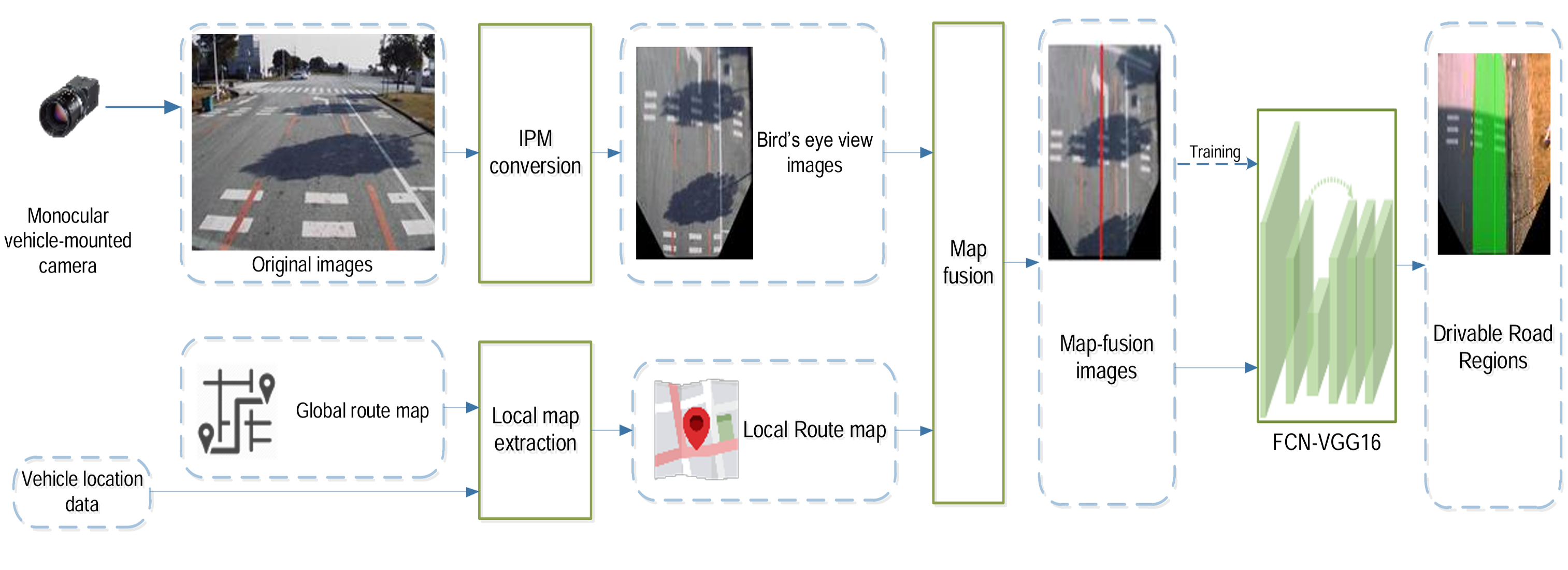 Robust drivable road region detection for fixed-route autonomous vehicles using map-fusion imagesYichao Cai, Dachuan Li, Xiao Zhou, and Xingang MouSensors, 2018
Robust drivable road region detection for fixed-route autonomous vehicles using map-fusion imagesYichao Cai, Dachuan Li, Xiao Zhou, and Xingang MouSensors, 2018Environment perception is one of the major issues in autonomous driving systems. In particular, effective and robust drivable road region detection still remains a challenge to be addressed for autonomous vehicles in multi-lane roads, intersections and unstructured road environments. In this paper, a computer vision and neural networks-based drivable road region detection approach is proposed for fixed-route autonomous vehicles (e.g., shuttles, buses and other vehicles operating on fixed routes), using a vehicle-mounted camera, route map and real-time vehicle location. The key idea of the proposed approach is to fuse an image with its corresponding local route map to obtain the map-fusion image (MFI) where the information of the image and route map act as complementary to each other. The information of the image can be utilized in road regions with rich features, while local route map acts as critical heuristics that enable robust drivable road region detection in areas without clear lane marking or borders. A neural network model constructed upon the Convolutional Neural Networks (CNNs), namely FCN-VGG16, is utilized to extract the drivable road region from the fused MFI. The proposed approach is validated using real-world driving scenario videos captured by an industrial camera mounted on a testing vehicle. Experiments demonstrate that the proposed approach outperforms the conventional approach which uses non-fused images in terms of detection accuracy and robustness, and it achieves desirable robustness against undesirable illumination conditions and pavement appearance, as well as projection and map-fusion errors.
